
Parquet y Tablas Delta en Fabric y Databricks
Un archivo Parquet es un formato de almacenamiento columnar optimizado para grandes volúmenes de datos y ampliamente utilizado en plataformas de big data como Databricks y Microsoft Fabric. A continuación, te explico qué es, sus características y cómo encaja en estos entornos:
¿Qué es un archivo Parquet?
El formato Parquet es un tipo de archivo que almacena datos de manera columnar (por columnas, no por filas) y fue diseñado para mejorar la eficiencia de almacenamiento y lectura rápida de grandes volúmenes de datos. Se utiliza principalmente en entornos analíticos y big data donde se requieren consultas veloces.
¿Por qué usar Parquet en Databricks y Fabric?
En Databricks:
- Es un formato ideal para procesos de ETL y Machine Learning.
- Se usa en conjunto con Spark porque permite cargar grandes datasets de forma paralela y eficiente.
- Facilita la lectura selectiva de datos, algo clave en análisis complejos o modelos predictivos.
En Microsoft Fabric:
- En Fabric (orientado a la integración de datos y análisis en tiempo real), Parquet permite trabajar con datos en Lakehouses y pipelines de datos, aprovechando la eficiencia del formato.
- Fabric se conecta fácilmente con Azure Data Lake, donde Parquet es el formato preferido para almacenar datos históricos y masivos.
Un archivo Parquet es un formato de almacenamiento columnar optimizado para grandes volúmenes de datos y ampliamente utilizado en plataformas de big data como Databricks y Microsoft Fabric. A continuación, te explico qué es, sus características y cómo encaja en estos entornos:
¿Qué es un archivo Parquet?
El formato Parquet es un tipo de archivo que almacena datos de manera columnar (por columnas, no por filas) y fue diseñado para mejorar la eficiencia de almacenamiento y lectura rápida de grandes volúmenes de datos. Se utiliza principalmente en entornos analíticos y big data donde se requieren consultas veloces.
Características de Parquet
- Almacenamiento Columnar:
- Los datos se guardan por columna en lugar de por fila.
- Esto facilita la lectura de solo las columnas necesarias durante las consultas, ahorrando tiempo y recursos.
- Compresión Eficiente:
- Parquet utiliza algoritmos como Snappy y GZIP para comprimir los datos sin perder calidad, lo que reduce el espacio en disco.
- La compresión es más eficiente que en formatos como CSV o JSON porque las columnas suelen tener datos del mismo tipo (e.g., números, fechas).
- Optimización para Lectura y Consultas Analíticas:
- Las plataformas como Databricks o Microsoft Fabric pueden leer solo las columnas relevantes de un archivo, acelerando las consultas.
- Esquema Autodescriptivo:
- El archivo almacena el esquema de los datos (nombres y tipos de columnas), facilitando la integración y el análisis.
¿Por qué usar Parquet en Databricks y Fabric?
- En Databricks:
- Es un formato ideal para procesos de ETL y Machine Learning.
- Se usa en conjunto con Spark porque permite cargar grandes datasets de forma paralela y eficiente.
- Facilita la lectura selectiva de datos, algo clave en análisis complejos o modelos predictivos.
- En Microsoft Fabric:
- En Fabric (orientado a la integración de datos y análisis en tiempo real), Parquet permite trabajar con datos en Lakehouses y pipelines de datos, aprovechando la eficiencia del formato.
- Fabric se conecta fácilmente con Azure Data Lake, donde Parquet es el formato preferido para almacenar datos históricos y masivos.
Ventajas Comparadas con Otros Formatos
CSV: Menos eficiente en espacio y más lento en la lectura de columnas específicas.
JSON: Flexible, pero consume más espacio y tiempo de procesamiento.
ORC: Otro formato columnar, pero Parquet tiene mejor compatibilidad con herramientas como Spark y Fabric.
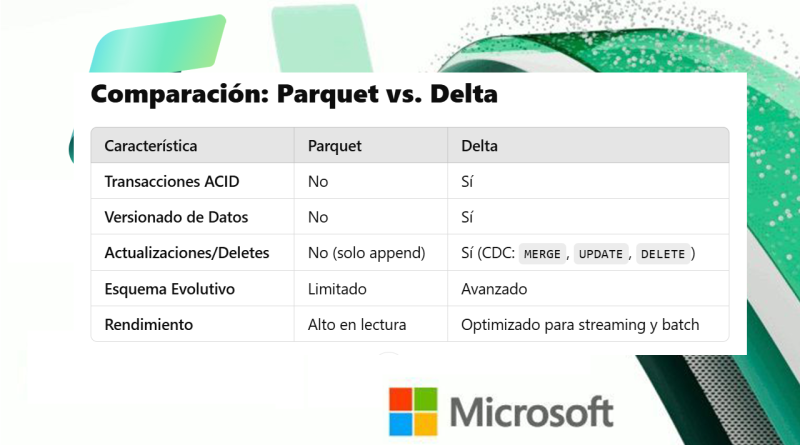
¿Qué es una Tabla Delta?
Una tabla Delta es una versión mejorada de las tablas Parquet, pensada para entornos con gran volumen de datos, ofreciendo consistencia, integridad y auditoría.
Características Clave de las Tablas Delta
ACID Transactions (Atomicidad, Consistencia, Aislamiento, Durabilidad):
- Las tablas Delta garantizan transacciones atómicas, es decir, todas las operaciones (como un
INSERToUPDATE) se completan en su totalidad o no se ejecutan, evitando datos incompletos o inconsistentes. - Ideal para procesos concurrentes, como múltiples usuarios actualizando la misma tabla.
Versionado de Datos (Time Travel):
- Delta almacena versiones previas de los datos, lo que permite «viajar en el tiempo» y acceder a estados históricos de la tabla.
- Es útil para auditorías y para restaurar datos a versiones anteriores.
Manejo de Cambios Incrementales (CDC – Change Data Capture):
- Soporta actualizaciones y eliminaciones (que no son fáciles de manejar con archivos Parquet simples).
- Permite merge de datos nuevos y existentes, lo cual es esencial para análisis en tiempo real y pipelines de datos.
Esquema Evolutivo:
- Las tablas Delta pueden adaptarse a cambios en el esquema (como añadir o modificar columnas), manteniendo la compatibilidad con datos antiguos.
Compacción Automática y Optimización:
- Durante la escritura de datos, la tabla Delta puede realizar compresión y compactación automática, mejorando el rendimiento al reducir la fragmentación.
Uso de Tablas Delta en Databricks y Fabric
En Databricks:
- Las tablas Delta son fundamentales para pipelines de datos complejos y procesos ETL.
- Permiten cargar datos en modo streaming (flujo continuo) o batch (procesos por lotes).
En Microsoft Fabric:
- Fabric permite integrar tablas Delta como parte de su arquitectura Lakehouse, lo que facilita la unificación de datos en un lago de datos con capacidad de análisis en tiempo real.
- Las tablas Delta se utilizan en pipelines de datos y reportes avanzados mediante Power BI y Synapse.