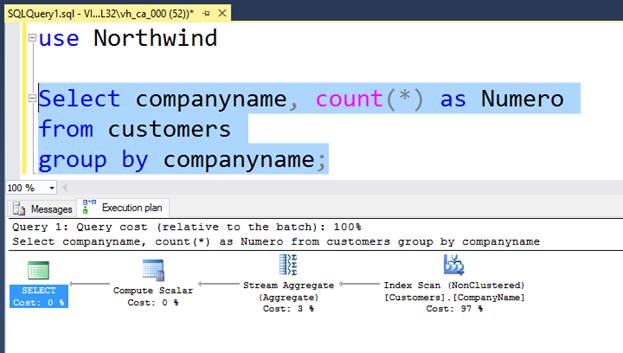
12 Operaciones básicas del plan de ejecución de SQL Server
Para hablar de planes de ejecución siempre pongo de ejemplo que supongamos necesitamos trasladarnos desde donde estamos ubicados al palacio nacional del país, para poder llegar lo más rápido posible deben considerar, las posibles rutas y su distancia, el estado de estas rutas y el tráfico que tienen, obviamente nos decidimos por la que consideramos la ruta más óptima.
Igual es el SQL Server y su motor de base de datos, que crea estadísticas al realizar las consultas basadas en costos de entradas y salidas de disco, tiempo de procesador y luego estas estadísticas le sirven para tomar la mejor decisión para devolver lo más eficiente posible una consulta.
Para visualizar de manera gráfica el plan de ejecución real o el estimado de una consulta es muy sencillo usar el SQL Management Studio de la siguiente manera:
Plan de Ejecución Estimado: Desde el Menú Consultas -> Mostrar Plan de Ejecución Estimado o con la combinación de teclas Ctrl + L. Esto no ejecutará la query sino más bien lo analizará y mostrará una aproximación del costo de su ejecución.
Plan de Ejecución Real: Desde el Menú Consultas -> Incluir Plan de Ejecución Real o con la combinación de teclas Ctrl + M. Con esta opción podremos ver el costo real de una query, pero a diferencia del anterior, se muestra al terminar la ejecución de la misma.
También es posible ejecutar la instrucción SET SHOWPLAN_ALL {ON | OFF }para devolver el plan de ejecución de manera plana, al ejecutar la consulta.
Tengamos en cuenta que los planes de ejecución se leen de derecha a izquierda, de arriba hacia abajo, y que es importante poder leer las operaciones que realizan y de ser necesario mejorarlas, esto se hace normalmente a través de la colocación de índices.
TABLE SCAN
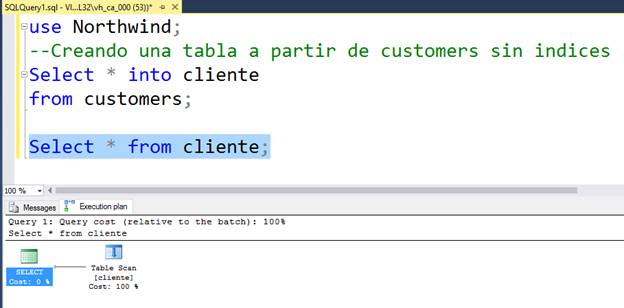
Si buscamos un tema en un libro sin usar el índice, sin un orden apropiado, tendríamos que ir hoja por hoja del libro hasta encontrar el tema necesitado, de la misma manera un Table Scan indica que el motor necesita leer completamente la tabla sin utilizar un índice porque no existe o porque los que existe no le son funcionales, lo cual la mayor parte del tiempo es deficiente, debemos tener en cuenta que el motor de base de datos siempre intenta predecir los costos de ejecución basados en las estadísticas que va almacenando, también menos frecuente pero puede darse el caso existiendo índices que el motor estime que va ser más rápido leer toda la tabla en vez de leer un índice, esto suele suceder con tablas poco pobladas y la consulta en cuestión no conlleva ningún filtro, ya que reduce considerablemente el overhead. Ejemplo:
CLUSTERED INDEX SCAN
Similar al Table Scan pero en este caso la tabla cuenta con un índice clustereado que pre-ordena los datos, entonces esta vez recorre los datos ordenados, de cualquier forma es lento que recorra todo el índice :

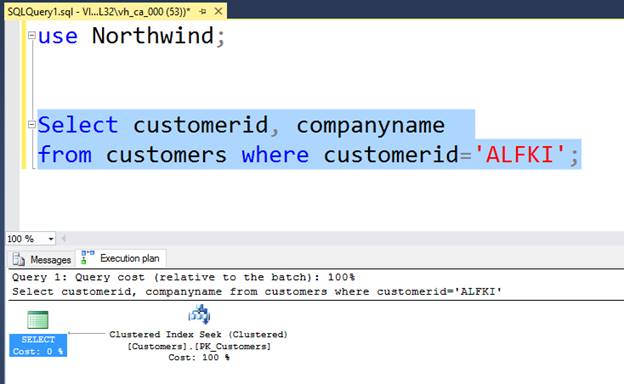
CLUSTERED INDEX SEEK
Esto si es eficiente, este tipo de acción es como buscar en la guía telefónica que sabemos que esta ordenada alfabéticamente por el nombre de la empresa, si buscamos a la empresa “Visoal” por ejemplo, no vamos a empezar a buscar desde la primera página que empieza por la letra “A” , vamos a buscar casi el final de la guía a partir de donde se encuentra los de la letra “V”, similar a este ejemplo los datos en un índice clustereado están ordenados físicamente en el disco y el icono que se muestra abajo es para indicar que está usando este tipo de índice para buscar el registro necesitado Ejemplo:
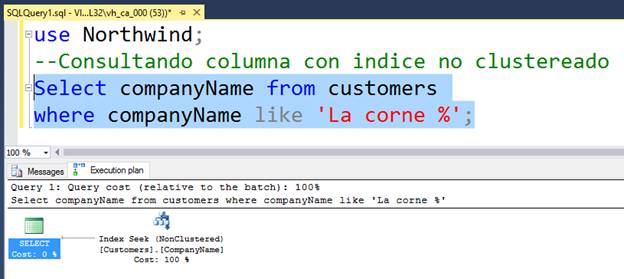
INDEX SCAN
Similar a Table Scan y Clustered Index Scan, pero un poco más eficiente.
Digo esto porque un índice no clustereado al no poder ordenar los datos físicamente porque esto ya lo hizo el índice clustereado, crea una estructura adicional con las columnas que va a indizar y ordena estas columnas, si la consulta solo usa la estructura del índice sin llegar a tocar las páginas de datos esto no es perfecto, pero es más eficiente que Table Scan y Clustered Index Scan. Aunque muchas veces suele ser síntoma de un mal uso de los índices, también aparece cuando usamos las cláusulas ORDER BY, JOIN o GROUP BY.

INDEX SEEK
Esto es el perfecto uso de un índice Non-Clustered el concepto es similar a buscar un tema en un libro, donde recurrimos al índice del libro en las primeras hojas para localizar la página donde está la información a consultar:
BOOKMARK LOOKUP
Dijimos con anterioridad que el Non_Clustered Index crea una estructura adicional a los datos con las columnas que va a indizar, ordena estas columnas y luego crea apuntadores a los datos, para entender el panorama completo piense en un índice de un libro, donde el mismo índice es la estructura a la que me refiero, creada al inicio del libro y las páginas con ya el contenido propio del libro son las páginas de datos.
Cuando las columnas que se indizaron no son suficientes para devolver la consulta se requiere hacer un salto del apuntador del índice non-clustered a la páginas de datos real. Una de las maneras para evitar su aparición excesiva es limitar los campos requeridos en la consulta, sólo solicitar los que están incluidos en el índice, ésta es la principal razón por la que habrán escuchado más de una vez, “no escribas consultas SELECT * FROM..“.
En algunos casos extremos (repito, muy extremos) se podría considerar la inclusión de todas las columnas de la tabla dentro del índice.
Una de las mejoras que se introdujo a partir de SQL Server 2005, es que en los índices Non-Clustered se pueden agregar o copiar el contenido de las columnas, sin que estas sean parte del índice en sí, es decir, que no servirán para realizar búsquedas ni filtros, pero si para desplegar los datos rápidamente, sin tener la necesidad de usar el puntero para buscar las páginas de datos en la tabla. Esta característica debe usarse con cuidado, ya que podría reducir considerablemente el costo de las consultas, pero también al tener más datos los índices, estos crecen rápidamente porque ocupan más espacio y por ende se tienen menos Llaves por cada página de índice lo que podría llegar a aumentar el nivel de entradas y salidas de disco. Así que, deben considerar el contexto para utilizarlo.
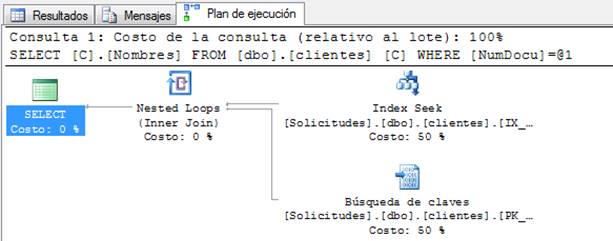
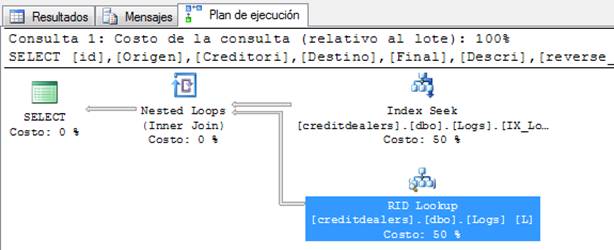
RID LOOKUP
Este operador no es muy frecuente de ver, y normalmente aparece cuando el motor intenta optimizar por su cuenta la consulta y no tenemos un índice agrupado (Clustered) entonces buscará a través del índice único ROW ID (de ahí el nombre RID). Si requiere solución este tipo de operaciones es muy dependiente de caso. Ejemplo
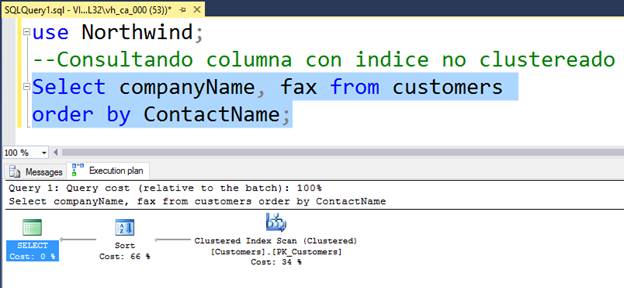
SORT
Cuando el motor de base de datos necesita ordenar por un campo que no está pre-ordenado por un índice clustereado o no clustereado necesita hacer la operación de ordenación que por lo general baja el rendimiento de la consulta gastando tiempo en ordenar los datos, se usa cuando aplicamos la cláusula ORDER BY, GROUP BY, TOP, etc.
JOIN
Existen tres tipos de JOIN, el Merge el más eficiente, luego Nested y Hash. Entran en acción cuando se hacen uso de las cláusulas JOIN para unir dos o más tablas en la consulta y está determinado por el orden de las columnas que se usan en el join para que SQL Server elija usar uno u otro.
NESTED LOOP JOIN
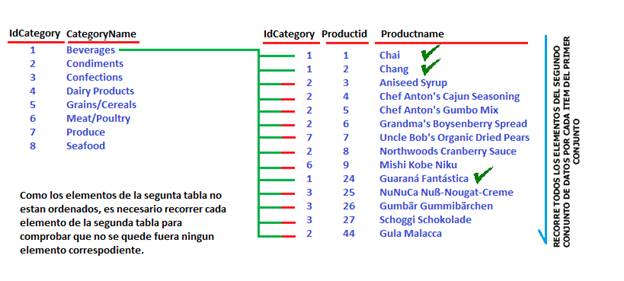
Para explicar este operador piense que unirá dos conjuntos de datos (Tablas) donde uno esta pre-ordenado y con elementos únicos (Por un índice) y el otro no, tomando como base el conjunto ordenado y de ítems únicos elegirá el primer elemento y buscara su correspondiente mach con cada elemento del segundo conjunto, recorriendo todos los elementos porque el segundo conjunto no están ordenado, al terminar e iniciar con el segundo elemento es imposible que exista nuevamente el primer elemento y que quede algún mach con el segundo elemento porque para esto estaba previamente ordenado. Esto es el operador Nested
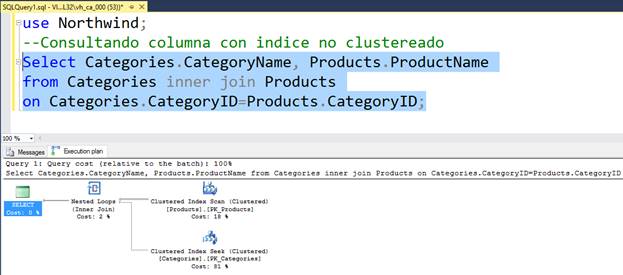
MERGE JOIN
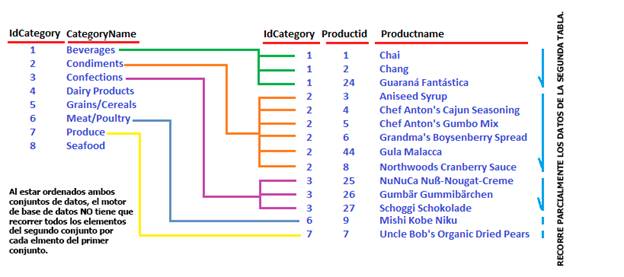
Este operador es el más eficiente de los Joins y en este caso tanto el primero conjunto de datos como el segundo están ordenados, lo que hace una búsqueda más eficiente en el segundo conjunto. Nuevamente cada elemento del primer conjunto busca hacer mach con los ítems del segundo conjunto, pero al estar ordenado el segundo conjunto, al ya no existir más coincidencias ya no es necesario recorrer toda la tabla por cada elemento del primer conjunto.

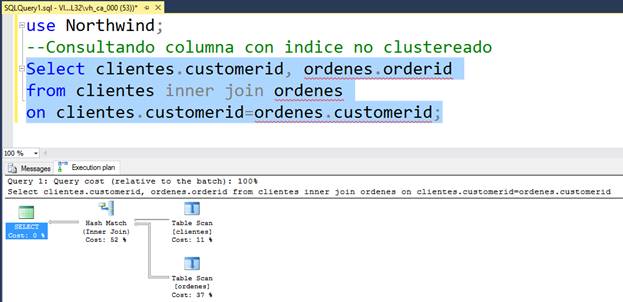
HASH JOIN
Este es el más deficiente de los Join, ya que, al no encontrar un ordenamiento valido a través de índices en ninguna de las dos tablas o conjunto de datos (es decir no hay índices en ninguna tabla), tiene que crear una tabla temporal ordenada para sustituir uno de los conjuntos y luego emular un join como el Nested Loop.
STREAM AGGREGATE
Aparece cuando agrupamos los datos, y mezclamos con funciones de agregado como MIN, SUM, AVG, también con la cláusula HAVING. También es frecuente ver que este operador lleva acompañado a SORT, a quien utiliza para ordenar primeramente los datos antes de agrupar.